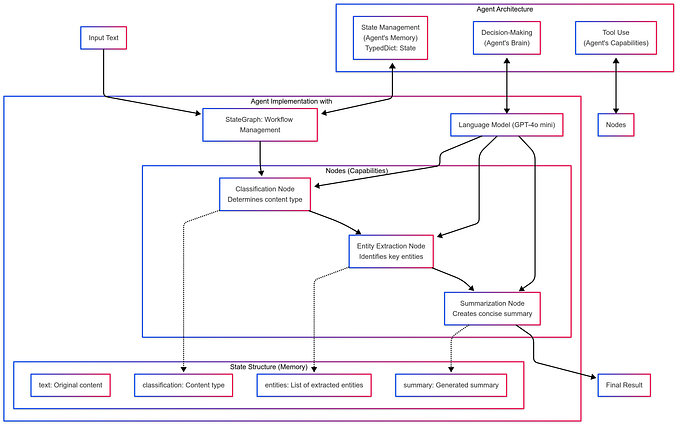
The 2023 edition of the Machine Learning, AI and Data Landscape — a quick analysis
The latest MAD (Machine Learning, AI and Data) Landscape is out again! A huge kudos for the tremendous work Matt Turck and the team FirstMark Capital have done putting the analysis together 🙌
In this year’s landscape, there are 1,426 companies, compared to 139 companies in the first landscape from 2012. This represents an +1,000% increase in a decade!

I know how easy it is to make comments from the sidelines, but here are a few spontaneous thoughts from yours truly after skimming through the landscape.
Lack of an Embedded DB category
I find it a bit surprising that they decided to — at least for now — leave embedded databases out of the landscape. I wrote last year a blog post here on Medium about the hype around DuckDB that went semi-viral.
Embedded DBs are definitely having a renaissance:
- SQLite in RDBMS
- DuckDB in OLAP
- KuzuDB in Graph
- Chroma in Search
Based on the feedback I’ve heard, the developer experience is really good for the examples above.
Geographic bias in the Data and AI Consulting category
I appreciate that they have expanded the data & AI/ML consultancy category, as consultancies are a huge contributor to the data community and don’t get even close to the same attention as heavily funded data or ML infra startups. This being said, it’s a bit of a two-sided sword to expand this category, as there are so many strong consultancies in different geographies. Right now the category is extremely heavily biased toward North America and I can quickly count 20 European top-tier data and AI/ML consultancies that would easily deserve to be on the landscape (Syntio, Silo.AI, GetInData to quickly name a few).

Merging the Data Quality and Data Observability categories
I think merging the Data Quality and Data Observability categories makes a lot of sense, as software providers in these categories are using terms interchangeably and inconsistently — while often referring to the same thing.

It has been crazy to witness the explosion of the data quality/observability category since I started looking more deeper into it in late 2019. This after being involved in +20 machine and deep learning projects and realizing the main bottleneck for successful operationalization of AI/ML almost always was coupled with data quality — not the algorithms per se (which are becoming increasingly commoditized).
Renaming the Horizontal AI category to Horizontal AI / AGI
I love that they renamed the “Horizontal AI” category to “Horizontal AI / AGI” to reflect the emergence of a whole new group of research-oriented outfits, many of which openly state Artificial General Intelligence (AGI) as their ultimate goal. Even though Large Language Models and Foundation Models are very impressive engineering feats, they’re not close to being anything comparable to real human intelligence. It’s well known within the O.G. AI/ML community that current Deep Learning architectures are inadequate for solving AGI. Why? In short, it’s because Deep Learning can’t generalize. I recommend reading this article from November to learn more. This is one of the reasons I’m so excited about European companies creating new architectures for getting closer to horizontal AGI such as Intuicell.

What’s noteworthy is the fact that the category is right now as depicted in the landscape over-represented with companies (and organizations) mostly focusing on LLMs and generative AI, not really horizontal AGI.
Lack of a FinOps category despite increasing momentum
I’m a bit surprised that there’s no category for FinOps yet in the landscape, even though it’s becoming an increasingly hot topic, especially in the data community (you can e.g. just ask Benjamin Rogojan). In short, FinOps is an evolving cloud financial management discipline and cultural practice that enables organizations to get maximum business value by helping data/ML/software engineering, DevOps, finance & business teams to collaborate on data-driven spending decisions. One can just look at e.g. Google Trends data to see the growing momentum within FinOps as we’ve entered a new paradigm in cloud economics and multi-cloud management. The exploding interest in FinOps is one of the reasons I’m so excited about European startups in the space such as Holori.
In conclusion
A huge thank you to Matt and the team at Firstmark for once again putting this together. Access the full report here including a new interactive version of the landscape: https://mattturck.com/mad2023/
The data and AI/ML space have been the gift that keeps on giving, both for founders and investors. This megatrend has been playing out for a few decades already, and it’s likely to continue for a long time — with some consolidation on the horizon.